DANTE DYNAMIC MAPPING
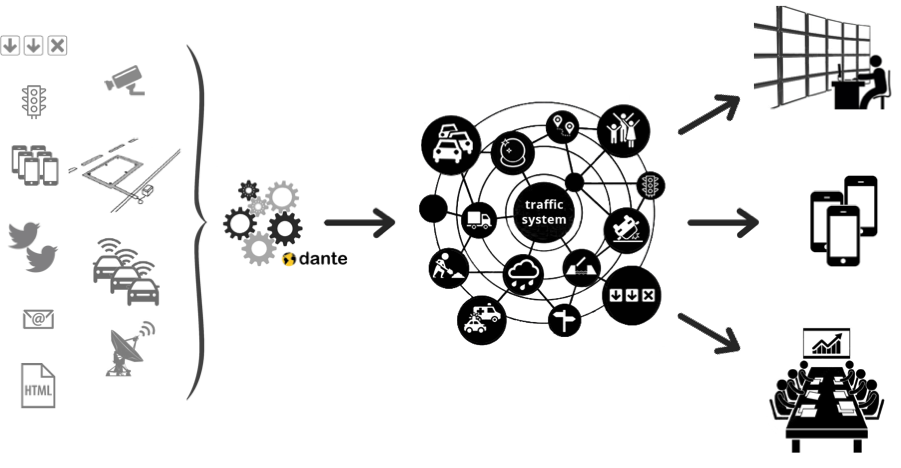
Dante in brief
- Modular GIS software platform
- Time slider for temporal changes
- Big data ready
- Hierarchically organised spatial data
- Fast configuration of new sources
- Data type independent
- Launch directly from the browser
- Geographic web services hosting
- Available through an API
Due to the modular approach, Dante is highly configurable during all three steps of development
Some examples of the variability of the model-view-controller, without aiming at completeness:
-
Data

Formats
- Json, XML, Protofub
- openLR, datex2, NTCIP
- CSV, excel, noSQL, SQL
Sources
- Opensreetmap, Twitter, weather services, websites
- Propriatery software programs: shapefiles, autocad, vissim, matlab, etc
- Video feeds, country specific traffic sources for NL, UK
-
Model

Standardization
- Elements define a location in time and space
- Dataobjects linked to elements
-
Control
Industry standard techniques
- Java8
- OSGI
- Jetty/Netty
Standardization of data sources as a first step
- Link, nodes, segments, areas
- Algorithms work with standardised data
Traffic Algorithms
- Queue tracking on motorways and cities
- Shockwave tracker
-
View

Rich html5 app for browser and mobile
- Interactive map with options to dinamically adjust time
- Situational Awareness: focus only on extra-ordinary eventualities
- Traffic 360, zooming-in/out adjusts datasource volume and intensity to reflect scope
- Leveraging NodeJs, LeafletJs, Meteor
Just Three Simple Steps: Data, Analytics and Dissemination
Any kind of Data
Flexible & Customizable data input.
Any type of data source can be assimilated. So far the following sources have been made accessible: open streetmap, openLR, loop detectors, bluetooth, floating car data, radar detector, video, weather imagery, structured feeds e.g. RSS, Datex2, unstructured data from twitter or websites. In general connecting to an API, accessing a known database or assimilating data directly from a collection of sensors is a routine task. And more is on the way.
Trackers & Algorithms
Past Present & Future Analytics.
A tracker is our construct to record any type of geo/spatial phenomena and we have applied it to congestion. We use trackers for regular (bottleneck) congestion, urban queues, shockwaves and incidents. We use databases of traces for our past analytics or as input to our prediction engine and always have trackers follow the current state of traffic on our networks.
Browser, API or mobile App
Dissemination via HTML5 or API.
All information is made accessible via internet on our traffic browser just like Google maps but with a dynamic map that changes when you change the time slider. It is accessible on all html5 capable device, secure, build on standards such as leaflet, meteor and node js.
Off-the-Shelf Modules
We have a rich set of pre-configured modules that are ready to be deployed.











